webdesign / development + awesome
Upload progressbar s PHP a jQuery
napísal blade, 1 Nov 2010
Pri uploadovaní cez HTML formulár, hlavne ak sa jedná o veľké súbory, môže byť problém, že používateľ nevie aká časť zo súboru sa uploadla, či sa súbor vôbec uploaduje a prinajhoršom si myslí, že sa vôbec nič nedeje a nervózne kliká na submit. Ešte horšie ako zvýšená záťaž na server, ktorú generuje, je riziko, že sa na celú stránku vyserie, lebo si myslí, že nefunguje. :)
V tomto tutoriale si povieme ako za pomoci PHPčka a jQuery jednoducho vytvoriť progress bar, ktorý sa priebežne obnovuje podľa množstva prenesených dát z uploadovaných súborov a snáď pomôže predísť úniku netrpezlivých používateľov zo stránky.
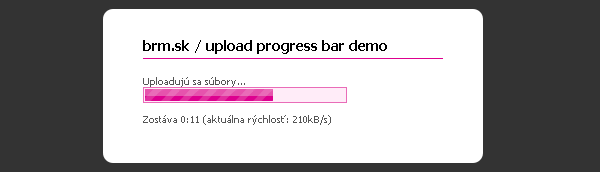
Aby ste vedeli o čom je reč, tu si môžete pozrieť demo.

 6 komentárov
6 komentárov
[ 


 ]
]
Generovanie pekných URL
napísal blade, 20 Oct 2010
Pre SEO sú veľmi dôležité vhodne formátované URL adresy. Taká dobrá URL by mala obsahovať viac menej len text úzko súvisiaci s obsahom, avšak bez diakritiky a podobnej chamrade, aby nevznikali problémy pri kopírovaní linkov a parsovaní adries vyhľadávačmi.
Chamraď sa dá buď nahradiť URL entitami (%20 je napríklad medzera), čo môže byť pri niektorých znakoch stále nespoľahlivé alebo sa z nej dá odstrániť diakritika a zvyšok nahradiť pomlčkami.
Druhý spôsob sa nám najviac osvedčil a používame naň túto funkciu:
function seo_url($str)
{
$str = remove_accents($str);
$str = preg_replace('/[^a-zA-Z0-9-]/', '-', $str);
return strtolower(trim(preg_replace('/-+/', '-', $str), "-"));
}
V prvom riadku sa odstáni z písmen diakritika:
Bŕm™ džžž DrÍST ブレイド! -> Brm™ dzzz DrIST ブレイド!
v druhom riadku sa nahradia všetky znaky okrem písmen a číslic pomlčkami:
Brm--dzzz-DrIST------
a v treťom sa všetky susediace pomlčky spakujú do jednej, odstránia sa pomlčky z krajov a všetky písmená sa premenia na malé:
Brm-dzzz-DrIST- -> Brm-dzzz-DrIST -> brm-dzzz-drist
Funkcia remove_accents() potom vyzerá nasledovne:
function remove_accents($str)
{
return str_replace (
array(
'à','á','â','ã','ä','å','æ','ç','ć','č','ď','đ','ð','è','é','ê','ë','ę','ě','ì','í','î','ï','ĺ','ľ','ł','ň','ñ','ò','ó','ô','õ','ö','ő','ø','ŕ','ř','ś','š','ß','ť','þ','ù','ú','û','ü','ű','ů','ý','ÿ','ž',
'À','Á','Â','Ã','Ä','Å','Æ','Ç','Ć','Č','Ď','Ð','È','É','Ê','Ë','Ę','Ě','Ì','Í','Î','Ï','Ĺ','Ľ','Ł','Ň','Ñ','Ò','Ó','Ô','Õ','Ö','Ő','Ø','Ŕ','Ř','Ś','Š','Ť','Þ','Ù','Ú','Û','Ü','Ű','Ů','Ý','Ÿ','Ž'
),
array(
'a','a','a','a','a','a','ae','c','c','c','d','d','d','e','e','e','e','e','e','i','i','i','i','l','l','l','n','n','o','o','o','o','o','o','o','r','r','s','s','ss','t','th','u','u','u','u','u','u','y','y','z',
'A','A','A','A','A','A','AE','C','C','C','D','D','E','E','E','E','E','E','I','I','I','I','L','L','L','N','N','O','O','O','O','O','O','O','R','R','S','S','T','TH','U','U','U','U','U','U','Y','Y','Z'
), $str );
}
Takýto "brute force" spôsob je momentálne jediný spoľahlivý a obdobná funkcia by oficiálne mala byť až v PHP 6. Konkrétne táto funkcia je využiteľná viac menej vo všetkých krajinách používajúcich latinku okrem Vietnamu a možno pár inch krajín, ktoré majú fakt divoké znaky a nechcelo sa mi nimi zapodievať ^^. Ak by aj náhodou neodstránila diakritiku, jediné čo sa stane je, že z URL vypadne daný znak.
ǚ
evil u is evil
[ ]
Bug v poli
napísal blade, 9 Oct 2010

...alebo skôr feature? Keď v PHP používate foreach s referenciou (&), treba si dávať veľký pozor. Môžu sa diať vcelku záhadné veci. Zoberme si takýto príklad:
$ciselka = array(1,2,3,4,5,6); foreach ($ciselka as &$cislo) $cislo *= 10; foreach ($ciselka as $cislo) echo "$cislo ";
V prvom foreach cykle všetky čísla v poli vynásobíme desiatimi a v druhom ich vypíšeme - triviálna vec, takže výsledok je úplne jasný:
10 20 30 40 50 60
Alebo aj nie? Ak to skúsite naozaj spustiť v PHP, uvidíte niečo trocha iné:
10 20 30 40 50 50 - WTF is goin' on?
Prečo sú posledné 2 prvky rovnaké? Cyklus foreach funguje tak, že do pomocnej premennej ($cislo) vždy kopíruje aktuálny prvok poľa a podľa toho, či pred ňu nedáme alebo dáme "&" sa buď do nej skopíruje hodnota aktuálneho prvku alebo odkaz/pointer na aktuálny prvok. V prvom cykle úkladáme do pomocnej premennej odkazy na prvky poľa, takže po skončení je v premennej $cislo odkaz na posledný prvok.
Ak by sme teraz premennej $cislo priradili hocijakú hodnotu, zmenila by sa aj hodnota posledného prvku poľa. A presne toto sa deje pri druhom cykle foreach - postupne, ako prechádzame poľom, sa priraďujú premennej $cislo hodnoty 10, 20, 30, 40, 50. Takže je logické, že keď prijdeme na posledný prvok, je v ňom hodnota predposledného prvku.
Ako tomu zabrániť? Nuž velice jednoducho. :p
Za prvý foreach stačí napísať unset($cislo). Premenná prestane existovať, odkaz sa zruší a v druhom cykle sa úplne nanovo vytvorí premenná $cislo, takže sa nič nebude prepisovať.
Je diskutabilné, či sa toto vôbec dá označiť ako bug... Na jednej strane prakticky nepredvídateľné, ale na druhej aj celkom logické. Asi preto je to v PHP nezmenené odvtedy ako existuje foreach s referenciou.
[ ]
Najrýchlejší úvod do vytvárania web stránok
napísal blade, 3 Oct 2010
Tento návod som sa rozhodol napísať, keďže už dosť ľudí po mne chcelo, nech im vysvetlím ako sa dajú tvoriť vlastné web stránky, ako to všetko okolo nich funguje a kde sa to naučiť. Samozrejme, že si môžu nakúpiť knihy, ale tie bývajú spravidla tak rozťahané, že ich veľa ľudí ani nedočíta. Plus zaťažujú množstvom detailov, ktoré na začiatku iba mýlia a zdržujú.
Preto píšem tento návod čo najstručnejšie, aby slúžil ako alternatíva k prehnane ukecaným knihám a aby ste namiesto zbytočného čítania mohli radšej kódiť. :p
Najskôr zbežný prehľad o tom, čo všetko sa deje, keď si v prehliadači otvoríte nejakú stránku. To aby ste vedeli kde sa vlastne používajú všetky tie technológie ako je HTML, CSS, PHP, SQL, JavaScript, jQuery, AJAX a iné.
1) Zadáte URL adresu - to je celý ten text, čo vidíte hore v address bare prehliadača.

2) Na základe názvu stránky (t.j. domény) sa zistí IP adresa servera, na ktorom sa nachádza hľadaná stránka. (Na toto slúži DNS server, ktorého adresu poznáme)

[ 


 ]
]
Problém s cache pri uploade obrázkov
napísal yablko, 25 Sep 2010
Ak vaša stránka podporuje (vlastnú implementáciu) ikoniek/avatarov je možné, že ste sa stretli s týmto - po uploade nového obrázku sa stále zobrazuje obrázok starý. Ak sa nový zobrazí po refreshi, samotný upload funguje. Obrázok sa však musí zobraziť hneď, nemôžte od ľudí očakávať zbytočný refresh, navyše je to confusing.
Problém je, že obrázku zrejme zostal rovnaký názov súboru, na čo si prehliadač povie "Heeej, toto som už raz sťahoval! To aby som to radšej vytiahol z cache! Mwahahahaa..", podhodí starú verziu a cíti sa múdro.
Jednoduchý spôsob ako ho oklamať je pridať na koniec názvu náhodne vygenerovaný reťazec znakov. Napr.:
<?php $randstr = base_convert(crc32(mt_rand()), 10, 36); $nazov = "$subor-$randstr.jpg"; ?>
Riešení je kopa, dobré je začať s náhodným číslom (alebo použiť uniqid(), čo vygeneruje reťazec na základe aktuálneho času v mikrosekundách), prehnať to cez nejakú tú hashovaciu funkciu (md5(), sha1()) a na koniec z toho vystrihnúť zopár znakov.
Takže - pridajte niekoľko náhodných znakov do názvu súboru a prinútite browser vyhnúť sa cache pamäti. *lusk*
[ ]


